

How does OpenAI's DALL-E 2 work?
An overview of how OpenAI's DALL-E 2 works


If you're not familiar with OpenAI's DALL-E 2, see OpenAI's introductory video and the research paper explaining it.
DALL-E 2 uses multiple neural networks. To understand how neural networks or other machine learning systems work, I wrote this.
DALL-E 2 uses OpenAI's CLIP neural networks. To understand how CLIP embeddings work, please take a look at this explanation. For comparison, here are 10,000 CLIP text embeddings versus 10,000 CLIP image embeddings:


The system consists of a few components. First, CLIP. CLIP is essentially a pair of neural networks, one is a 'text encoder', and the other is an 'image encoder'. CLIP is depicted in the image below above the dotted line.
CLIP is trained on a giant dataset of images and corresponding captions. The image encoder takes as input an image, and outputs a numerical description of that image (called an 'embedding'). The text encoder takes as input a caption and does the same, outputting an embedding. The networks are trained so that the encodings for a corresponding caption/image pair are close to each other.
CLIP allows us to ask "does this image match this caption?".
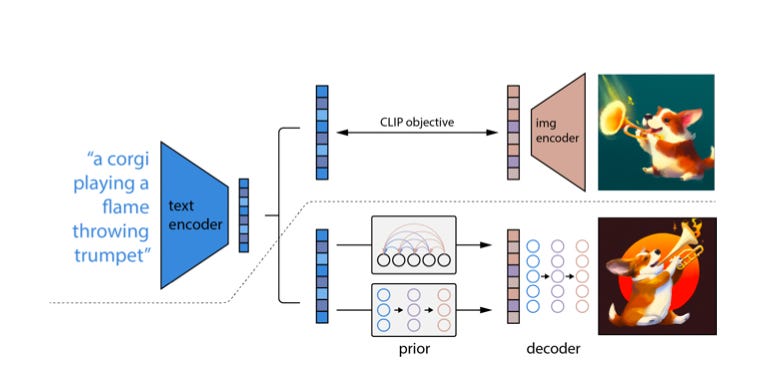
The second part of how DALL-E 2 works is an image generator, which is depicted below the dotted line. It is formed by two parts: A “prior” and a diffusion decoder. Its goal is to be the reverse of the CLIP image encoder (or unCLIP). There are two parts of it.
The ‘prior’ job is to take the encoding of a text prompt (generated by CLIP), and predict the encoding of the corresponding image. You might think that this is silly - CLIP was supposed to make the encodings of the caption and the image match! But the space of images and captions is not so simple - there are many images for a given caption, and many captions for a given image. I think of the "prior" as being responsible for picking which picture of "a teddy bear on a skateboard" we're going to draw.
The next part, the “diffusion decoder”, uses a process called 'diffusion'. Imagine you started with a real image, and slowly repeatedly added noise to it, step by step. Eventually, you'd end up with an image that is pure noise. The goal of a diffusion model is to learn the reverse process - given a noisy image, produce a slightly less noisy one, until eventually you end up with a clean, realistic image.
This is an interesting way of generating images, but it has some advantages compared to GANs. One advantage is that it allows the system to build up the image step by step, starting from the large scale structure and only filling in the fine details at the end.
That’s how the whole system works and how it is trained.
For creating an image from a caption, you have all these neural networks trained. The system takes the prompt, and ask CLIP to encode it. The CLIP encoding is given to to the prior, which predicts the image encoding. The "diffusion decoder” then takes the image embedding and produces the final image!

Why does it work so well?
First, OpenAI collected a large dataset of image/caption pairs and had a huge amount of compute training it.
The training dataset for OpenAI's CLIP neural networks consists of 400 million image+caption pairs.
Second, diffusion models are really good at making realistic images - previous works have used GAN models that try to generate a whole image in one go. Some GANs are quite good, but so far diffusion seems to be better at generating images that match a prompt. The value of the image generator is that it helps constrain the output to be a realistic image. We could have just optimized raw pixels until we get something CLIP thinks looks like the prompt, but it would likely not be a natural image. It would might get something very close to the “original” image that pairs with the caption but that has a lot of noise or doesn’t look just right.
In other text-to-image algorithm the basic idea is to encode the text, and then try to make an image that maximally matches that text encoding. But this maximization often leads to artifacts. For example, if you give the caption of a “sunset”, it will often gives multiple suns, because that is even more sunset-like. There are a lot of tricks and hacks to regularize the process so that it's not so aggressive, but it's always an uphill battle.
Here, they instead take the text embedding, use a trained model (a 'prior') to predict the corresponding image embedding - this removes the dangerous maximization. Then, another trained model (the 'decoder') produces images from the predicted embedding.
If you want to understand more how systems like this work I recommend taking a look at this.
A good reference that helped me inform how DALL-E 2 works: DALL-E 2 ELI 15 on hacker news also this reddit post.
